AI Compute Shortage & Infrastructure Crunch in 2025: What Businesses Need to Know to Stay Ahead?
By JPStechsolutions
Introduction
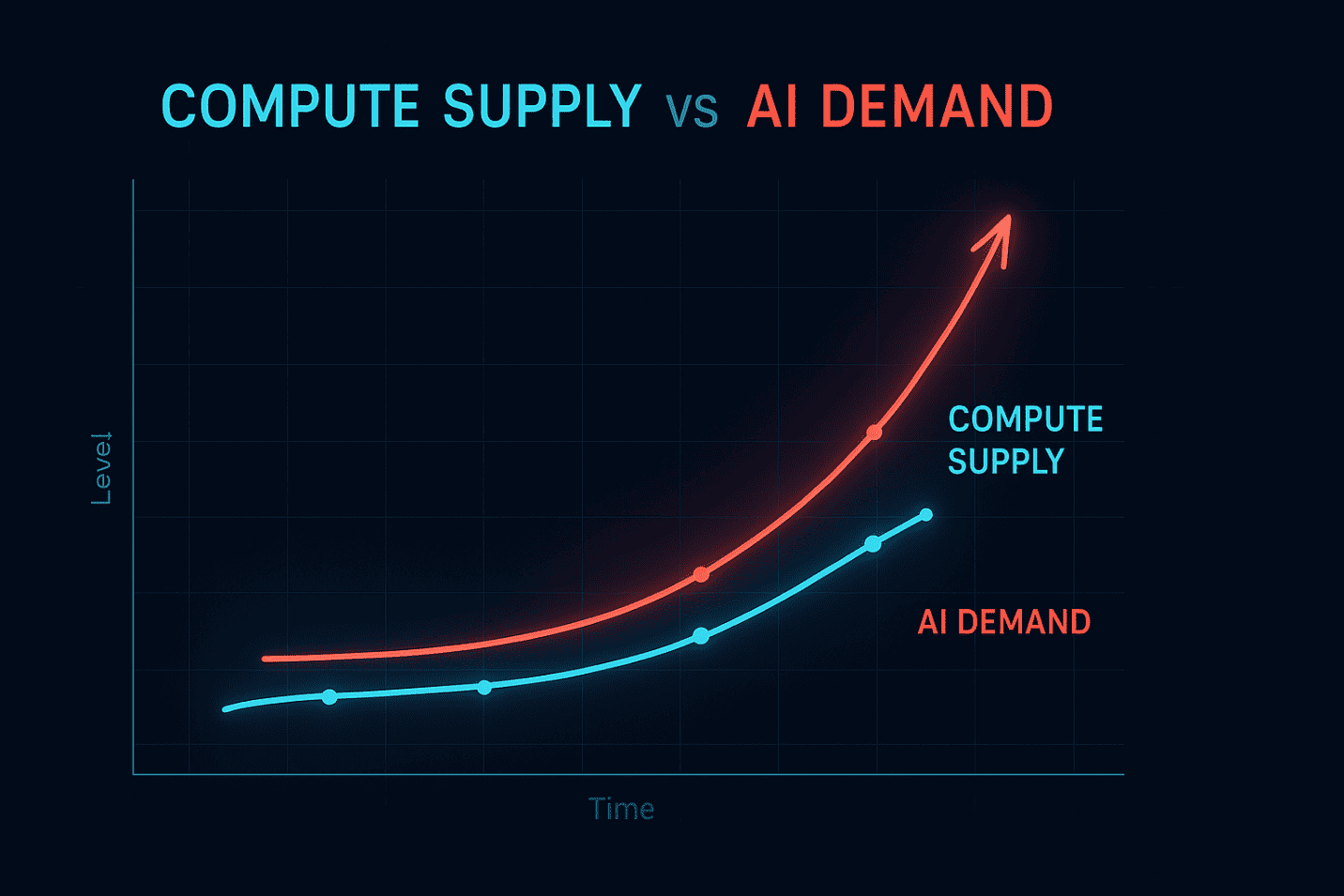
The global race to scale artificial intelligence has created a new kind of resource crisis — not oil, not electricity, but compute power. In 2025, businesses around the world are struggling to secure enough GPUs, TPUs, high-performance compute clusters (HPC), and data-center capacity to support AI workloads.
The shortage is real. Demand for compute power is growing 10x faster than global supply, cloud providers are experiencing long provisioning delays, and enterprises are competing for access to GPU hardware. The result: higher costs, scheduling bottlenecks, and slowed AI deployment timelines.
As AI becomes a fundamental business capability, compute availability will separate leaders from followers. Organizations that understand the implications today will gain a strategic advantage tomorrow.
Why the AI Compute Shortage Is Happening
Explosive Growth in AI Adoption
Generative AI, LLM training, agentic AI workflows, and enterprise automation require massive compute power. Organizations are scaling from thousands to millions of AI model inference calls per day.
Limited GPU Production Capacity
Companies like NVIDIA, AMD, and Intel cannot meet global demand fast enough — manufacturing and supply chain constraints slow expansion.
Cloud Providers Reaching Capacity Limits
Major cloud vendors (AWS, Azure, GCP) face provisioning delays for AI compute nodes.
Data Centers Need Huge Power & Cooling
Infrastructure expansion is restricted by energy availability and sustainability limits.
AI Models Are Getting Bigger
LLMs require increasing memory, bandwidth, and computational throughput.
Business Impact of the Compute Crunch
Impact
Result
High infrastructure costs
Cloud bills rising 2–4x YoY
Delayed AI project timelines
Model deployment slowdown
Resource competition
Limited access to GPUs / chips
Performance bottlenecks
Slower inference & training
Increased risk exposure
Falling behind competition
How do we scale AI when compute capacity is scarce and expensive?
✔ Focus on sustainable power-efficient architecture
✔ Partner with AI engineering & infrastructure experts
The companies that survive the AI compute war are those planning today, not reacting tomorrow.
The Future: Compute as a Competitive Advantage
The next stage of digital transformation will not be defined by apps, data, or even AI models — but by the ability to access, scale, and optimize compute resources.
Within the next 2–3 years, industry leaders predict:
Compute will be budgeted like real-estate or energy
Companies will differentiate based on AI efficiency, not size
Nations will compete for AI infrastructure supremacy
AI-as-a-Service capacity will be more valuable than cloud storage
AI agents + autonomous workflows will multiply compute demand
Compute will become the new currency of innovation.
Conclusion
The AI compute shortage is not a temporary challenge — it is a structural shift reshaping global competition. Organizations that modernize infrastructure, partner with experts, and build efficient AI architectures will emerge as market leaders. Those who wait will struggle to access the compute resources needed to compete in an AI-powered world.
At JPS Tech Solutions, we help enterprises design and scale AI infrastructure, optimize compute, and architect future-ready AI systems that deliver measurable ROI.
👉 Ready to build a scalable AI compute strategy? Talk to our experts today.